
Data backup is a crucial practice for anyone using Amazon S3 to store important information. While S3 provides reliable storage, it is not fully invulnerable to accidental deletions, data corruption, or potential cyberattacks. To protect your data, you must implement an effective Amazon S3 bucket backup strategy.
In this guide, we will take a look at the key methods to backup Amazon S3 buckets. We will focus on the use of AWS S3 versioning and Amazon S3 bucket replication to create a strong line of defense.
We will also help with using top-quality Amazon S3 backup software to automate and simplify the process. With these strategies, you can make sure your data stays protected and easily recoverable.
Why backup Amazon S3 bucket?
Backing up an Amazon S3 bucket is essential for data security and continuity, particularly in the face of data loss threats such as accidental deletions, cyberattacks, or corruption. Here is why it is critical to maintain backups for S3:
1. Protection against accidental deletions
Even though it is built for high durability, Amazon S3 does not stop accidental or intentional deletion. Versioning in S3 allows you to have the older versions of your objects, but a great backup strategy will make sure you can recover data at any point in time.
Thus, this will safeguard data from loss through unexpected deletion or modification and give companies as well as individual data owners assurance when using large datasets.
2. Disaster recovery
Some of the most important elements required from organizations that need uninterrupted access to data are disaster recoveries. Cross-region S3 bucket replication ensures the replication of your data within many AWS regions.
In any case of regional outage or natural disaster or infrastructure failures, you can still recover your data because it had previously been backed up in the geographically disparate region.
3. Granular data restoration
Comprehensive backup solutions like AWS Backup provide the capability to restore data at different levels—be it you need to recover a single file or an entire bucket. This flexibility is quite vital for meeting Recovery Point Objectives (RPO's) and Recovery Time Objectives (RTOs).
For instance, incremental backups capture only the changes made after an initial full backup and minimize storage costs along with the ability to restore data precisely to its last known good state.
4. Long-term data retention and cost management
Organizations often require the retention of data over long periods, either because of regulatory compliance or for business policies. A scheduled and lifecycle-managed backup plan allows the retention of data over months or years.
Transitioning older data to more economical storage tiers such as S3 Glacier enables organizations to minimize storage expenses without losing access to critical data.
Best methods for AWS S3 bucket backup
To backup Amazon S3 bucket, there are two basic go-to methods: (i) AWS S3 versioning (ii) AWS S3 bucket replication.
AWS S3 versioning
AWS S3 versioning helps to keep older versions of files for restoring later. With the use of versioning, you can easily safeguard data in a bucket from any kind of random & unwanted changes, corruption, or unauthorized deletion.
Whenever you make any changes to the file, a new version will be created of the objects stored in Amazon S3. We will now focus on how to enable Amazon S3 versioning:
- Log-in to the AWS Management Console and you must have full access to the needed permissions.
- Tap on Services and select S3 within the Storage category.
- From the navigation panel, tap on Buckets and select the S3 bucket for which you need to enable versioning for.
- Access Properties for the selected bucket.
- Tap on Edit within Bucket Versioning.
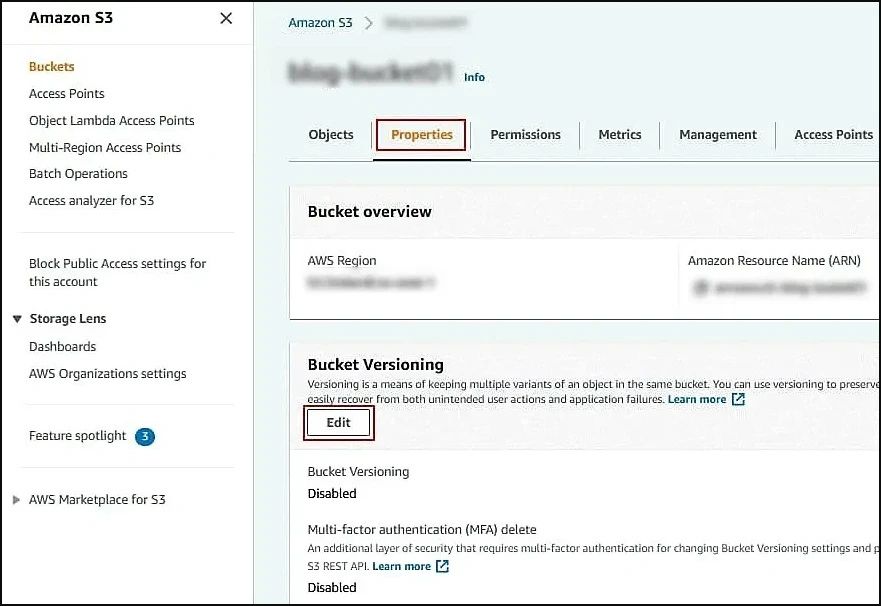
- You will see the default option for Bucket Versioning as ‘disabled’. Modify it to enable and click on Save Changes.
- The versioning will be now turned on.
- It is now time to set lifecycle rules. This means you need to put the settings as long as your data should be stored in the S3 bucket.
Here is how to configure lifecycle rules for Amazon S3 versioning:
- From the page of the selected bucket, go to the Management tab.
- Tap on Create lifecycle rule from the Lifecycle rules section.
- Put in the Lifecycle rule name.
- Select a rule scope. Apply the Rule scope filters for specific S3 objects or all the objects within the current bucket.
- You can also add tags with a key and value in the appropriate lines and tap on Add tag. Remove tag if needed with the Remove button.
You can select from the specific actions for the rule.
- Transition current versions of objects between storage classes
- Transition previous versions of objects between storage classes
- Expire current versions of objects
- Permanently delete previous versions of objects
- Delete expired delete markers or incomplete multipart uploads
Check mark these two actions mentioned below:
1. Transition noncurrent versions of objects between storage classes
Set the storage class transitions and the no. of days for the objects to stay up to date.
2. Permanently delete previous versions of objects
Set the period in the no. of days, after which the previous object versions should be removed.
- Tap on Create rule to finalize creating a lifecycle rule.
- Amazon S3 bucket replication
Amazon S3 bucket replication means protection of your Amazon S3 data from permanent loss. In this, you need to create a destination bucket in a separate S3 region and then connect that bucket to the original one along with a replication rule. So, whatever changes are done in the original, it will be reflected in the created bucket.
Here is how to set the S3 bucket replication rule:
- Navigate to the Management tab and look for the Replication rules section. Tap on Create replication rule.
- Give a name for the rule.
- Set the rule status after creating the rule (enable or disable the rule).
- You have chosen the Source bucket before (blog-bucket01) but you can modify the source here.
- Select the rule scope to apply the created rule to all the objects, or limit the create rule for specific objects in the bucket.
- Set the Destination bucket and enter the name or tap on Browse S3 to select the required bucket from the list. If the source bucket has AWS S3 versioning setting turned on, the destination bucket should also have the object versioning setting enabled.
- IAM role means the identity and access management role, and it must also be configured. Set the role, the storage class and other replication options.
- Tap on Save for saving the settings and finalize the replication rule creation.
Stuck with the complex steps for backup Amazon S3 bucket? Need a better and easier option? Opt for a professional backup utility now. With their automated features and easy usage, these tools make your process easier, but which is the best one for you? We recommend using the Kernel Cloud backup tool, ideal for non-technical users looking to get away from Amazon backup complexities.
The Cloud backup tool helps you take secure backup of Amazon S3 buckets to the local system. With no size limitations, use this utility for rapid backup capabilities and assures zero data loss. Use advanced data filters and file filters for selective backup, and you can also verify the buckets and folders using the preview features.
It supports all the major versions of Amazon S3 bucket namely S3 Bucket, Amazon S3 several storage classes like, S3 Intelligent-Tiering, Standard-IA (Infrequent Access), S3 One Zone-IA (Infrequent Access), S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive, etc.
For more insights on the tool, you can go for the free trial version today.
Final say
With our guide, we have provided the best methods to backup Amazon S3 buckets. From AWS S3 versioning to AWS S3 bucket replication, you can choose the reliable method as per your convenience.
For non-technical users, we advise you to use the Amazon S3 backup tool. With its easy to navigate interface, top-quality features and wide range of compatibility, this tool is a must-have for all your Amazon S3 backup needs. Get your hands on the trial for free now.
FAQs
Q1. How big is the backup for S3?
AWS Backup for S3 imposes limitations on the size and number of objects in S3 buckets that can be backed up. Specifically, it supports backups for buckets up to 1 Petabyte (PB) in size and containing fewer than 24 million objects. These constraints are in place for efficient backup and restore operations, as well as to optimize resource utilization within the AWS Backup service.
Q2. Where the Amazon S3 data stored?
The storage location of S3 data depends on the storage class selected. For S3 One Zone-IA, data is redundantly stored within a single Availability Zone (AZ) in the chosen AWS Region. In contrast, S3 on Outposts stores data locally on your on-premises Outpost environment unless manually transferred to an AWS Region. This flexibility allows you to optimize data storage based on your specific needs.
Q3. How long is data stored in S3?
S3 data retention depends on the storage class. For S3 Glacier Deep Archive, data must be stored for a minimum of 180 days. Retrieval options include standard retrieval within 12 hours and bulk retrieval, which is more cost-effective but takes up to 48 hours.



